ニューラルネットワークを使ってワインの種類を分類する
今回はscikit-learnに含まれるワインのデータセットを使って、ニューラルネットワーク(以下、NNと呼ぶ)による分類を学んでいきます。
大まかな流れは以下の通りです。
- 13個の特徴量(input layer)を持つワインのデータセットを用意
- 隠れ層(hidden layer)を通して、出力(output layer)を計算
- 出力値と正解値から誤差を計算
- 誤差を逆伝搬し、重み(パラメータ)を更新
- 処理を繰り返し最適解(モデル)を探す
では早速、コードを書いて実行していきましょう。
'''ライブラリの準備'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import pandas as pd
'''データセットの準備'''
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split

まずは学習に必要なライブラリとデータセットを読み込みます。
ライブラリに関する説明は前回の記事で説明したので、今回は割愛いたします。
'''データの読み込み'''
wine = load_wine()
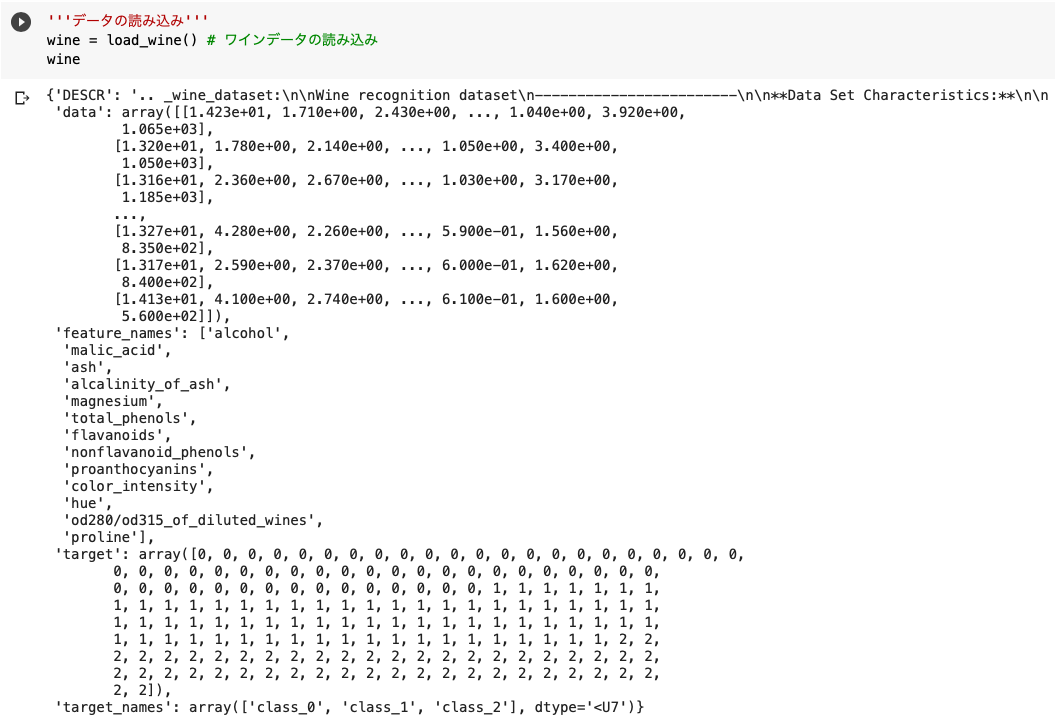
まずは今回利用するデータセットの中身を確認します。
ここではデータセットをwineという名前で登録しました。
wine_df = pd.DataFrame(wine.data, columns=wine.feature_names)
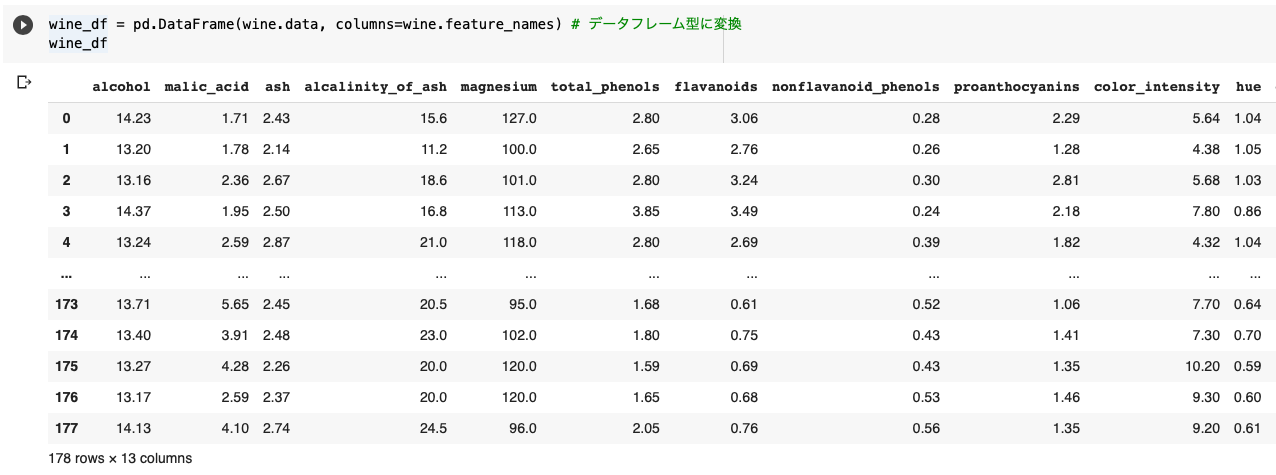
先ほど取り込んだワインデータをデータフレーム型(DataFrame)に変更します。
データフレーム型は、加工や抽出などデータ解析に必要な操作ができるのでとても便利です。
wine.dataでwineというデータセットの「data」を参照し、カラム名(列名)には「feature_names」をセットしました。
※この「data」「feature_names」はデータセットによって名前が異なります。
wine_class = pd.DataFrame(wine.target, columns=['class'])
先ほど作成したwine_df(ワインの特徴が入ったデータ)とwine_class(ワインの種類:0 or 1)を結合するために、DataFrame型に変換しました。
'''学習データの準備'''
wine_cat = pd.concat([wine_df, wine_class], axis=1)
wine_cat.drop(wine_cat[wine_cat['class'] == 2].index, inplace=True)
wine_data = wine_cat.values[:,:13]
wine_target = wine_cat.values[:,13]
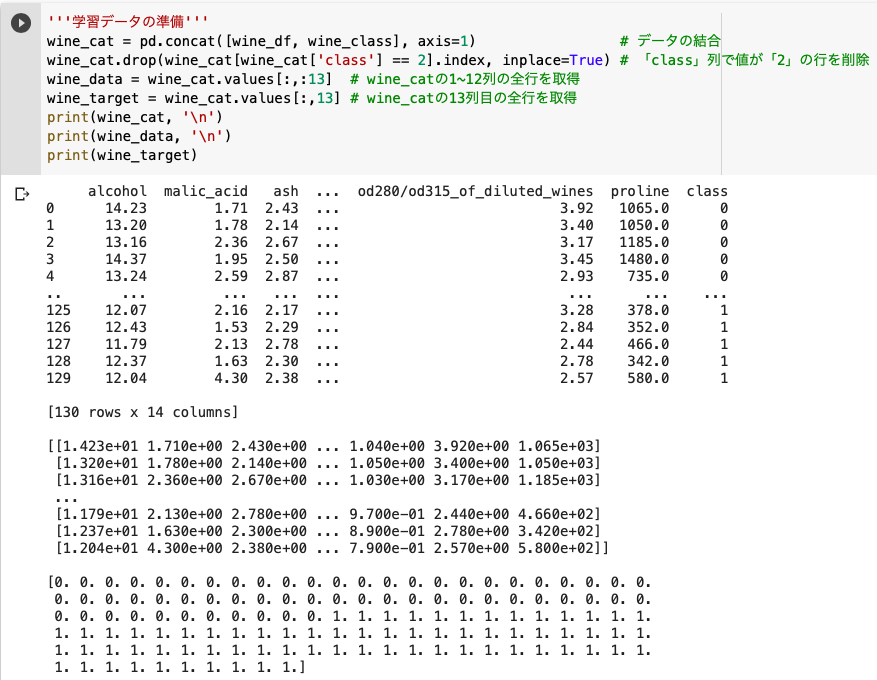
pd.concatでデータを結合。axis=1は横方向を意味します。
.indexは行番号を示しており、dropでそのデータを削除することができます。
また、inplace=Trueで結果をそのままwine_catに代入しました。
.valuesを使うとDataFrameの値を配列として取得でき、wine_data.values[行, 列]で任意の行・列を参照します。
※[:, :13]=[全行, 0~12列目]。[:, 13]=[全行, 13列目]。
※print()内の「’\n’」は改行を意味します。
'''データセットの分割'''
Train_X, Test_X, Train_Y, Test_Y = train_test_split(wine_data, wine_target, test_size=0.25)
'''PyTorch tensorへ変換(型指定)'''
train_X = torch.FloatTensor(Train_X)
train_Y = torch.LongTensor(Train_Y)
test_X = torch.FloatTensor(Test_X)
test_Y = torch.LongTensor(Test_Y)
train = TensorDataset(train_X, train_Y)
◆データセットの準備
まずは、train_test_splitで学習用データとテスト用データに分割します。
(ここでは25%をテスト用データとしました)
◆PyTorch tensorへ変換(型変換)
ただ、これはまだtensor型ではないので、FloatTensorなどを用いてTensor型に変換します。
※メモリの負荷を下げるために今回は32bit小数のfloatを採用しました。
tensor型に変換できたらTensorDatasetを使って、train_Xとtrain_Yを一つにしたtensor型データセットを作成します。
train_loader = DataLoader(train, batch_size=8, shuffle=True)
![]()
DataLoader:データセット(train)からサンプルを取得してミニバッチを作成。
「batch_size=8」「shuffle=True」とすることで、データをシャッフルし、8個のデータをまとめて学習できるようにしました。
'''モデルの定義'''
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(13, 128)
self.fc2 = nn.Linear(128, 2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
net = Net()
'''最適化手法の定義'''
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)

◆モデルの定義
PyTorchでクラスを作成するときは通常、nn.Moduleを継承します。
※すでに存在するクラスを継承すると何かと楽です。
<クラス作成時の公式>

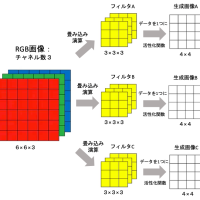
結合層(入力層・隠れ層・出力層)のイメージはこちらです。
結合層では主に「nn.Linear:線型結合」「Conv2d:画像データの畳み込み計算」などが使われます。
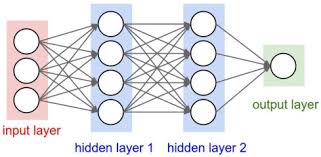
※toward data scienceより引用
そして順伝搬の処理(forward内)では、活性化関数「ReLU」を使用しました。
活性化関数とは数値をその関数に取り込んで計算結果を返すというものです。
※例えばReLUは「y=x(x>=0)、y=0(x<0)」という関数です。
◆最適化手法
評価方法には「CrossEntropyLoss(交差エントロピー誤差)」を採用しました。
前回の記事では「MSELoss(平均二乗誤差)」を用いたのですが、SGD(確率的勾配降下法)との相性の良さから、実際には交差エントロピー誤差が使われることが多いです。
※確率的勾配降下法は「微分から傾きを求めて損失関数が小さくなる方向に進むことで最適化を図る」という手法なので、微分計算が楽なlog(x)やe^xを含む交差エントロピー誤差は相性が良いのです。
※学習率とは、最適化の際にどのくらいパラメータを動かすかを決めるもので「0.01~0.03」あたりがよく使われます。
'''学習'''
for epoch in range(100):
total_loss = 0
for train_x, train_y in train_loader:
optimizer.zero_grad()
loss = criterion( net(train_x), train_y )
loss.backward()
optimizer.step()
total_loss += loss.data

今回はデータを500回学習させます。
1回の学習でtrain_loaderのミニバッチからデータを取り出し、予測値(net(train_x))と正解値(train_y)の損失を計算することで、最適なパラメータを探していきます。
学習がうまく進んでいるか確認したいので、50回に1回の頻度で結果を表示させました。
微小ではありますが少しずつ学習が進んでいる様子が観察できます。
test_net = net(test_X).detach()

先ほど学習が完了したので、実際にテストしていきたいと思います。
net(test_X)の値を取得するために、勾配を計算する演算情報を.detechで削除しました。
'''精度を計算'''
result = torch.max(test_net, 1)[1]
accuracy = sum(test_Y.data.numpy() == result.numpy()) / len(test_Y.data.numpy())
accuracy

2つの特徴量を持つtest_netの配列で*torch.max(詳細は後述)を用います。
そしてデータ型をtensorからnumpyに変換し、「torch.maxで求めた値(result)」と「test_Yの値(test_Y.data)」の一致率を求め、それを正解率としました。
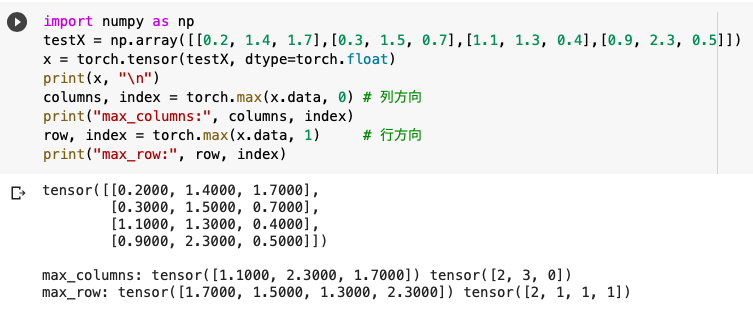
◆torch.max
torch.maxは配列内のある方向で「最大値とそのインデックス」を取得することができます。
※torch.max(x, 0)で列方向。torch.max(x, 1)で行方向。
◆test_Yとresultの中身

今回はニューラルネットワークの雰囲気を感じてもらいましたが、次回は画像識別データを使ってその精度を上げる方法について学びたいと思います。
参考文献
pytorchを用いたワイン分類
PyTorchでCNNsを徹底解説
Qiita – 交差エントロピー誤差をわかりやすく説明してみる




この記事へのコメントはありません。